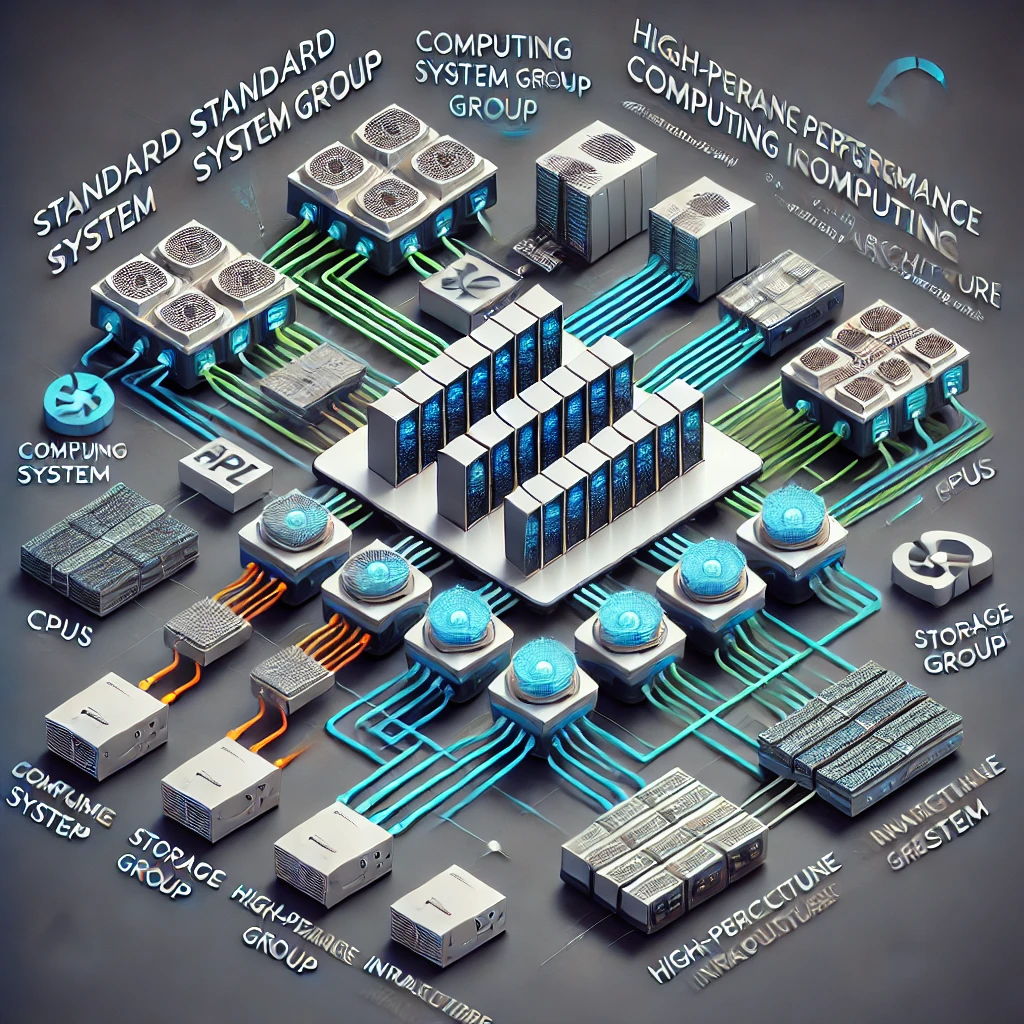
AI 및 고성능 컴퓨팅(HPC) 인프라는 다양한 규모와 목적에 맞추어 최적화된 시스템을 제공하기 위해 고도로 구조화된 표준 인프라 아키텍처를 따릅니다. 이 인프라는 주로 다음과 같은 네 가지 주요 구성 요소로 이루어져 있습니다: 컴퓨팅 시스템 그룹, 스토리지 그룹, 인프라 그룹, 관리 그룹입니다. 이들 구성 요소는 고성능 네트워크(Interconnect)와 관리 네트워크(Ethernet)를 통해 상호 연결되어 통합된 시스템을 구성합니다.

1. 컴퓨팅 시스템 그룹
컴퓨팅 시스템 그룹은 인프라의 핵심적인 연산 자원을 담당합니다. 이 그룹은 고성능의 CPU, GPU, NPU로 구성되며, 대규모 병렬 연산과 AI 학습/추론 작업을 효율적으로 처리합니다. 각 컴퓨팅 노드는 고속 네트워크를 통해 상호 연결되어, 대규모 작업을 분산 처리하고, 데이터 병목 현상을 최소화합니다. 이 그룹은 소규모 연구실부터 대규모 슈퍼컴퓨터에 이르기까지 확장 가능합니다.
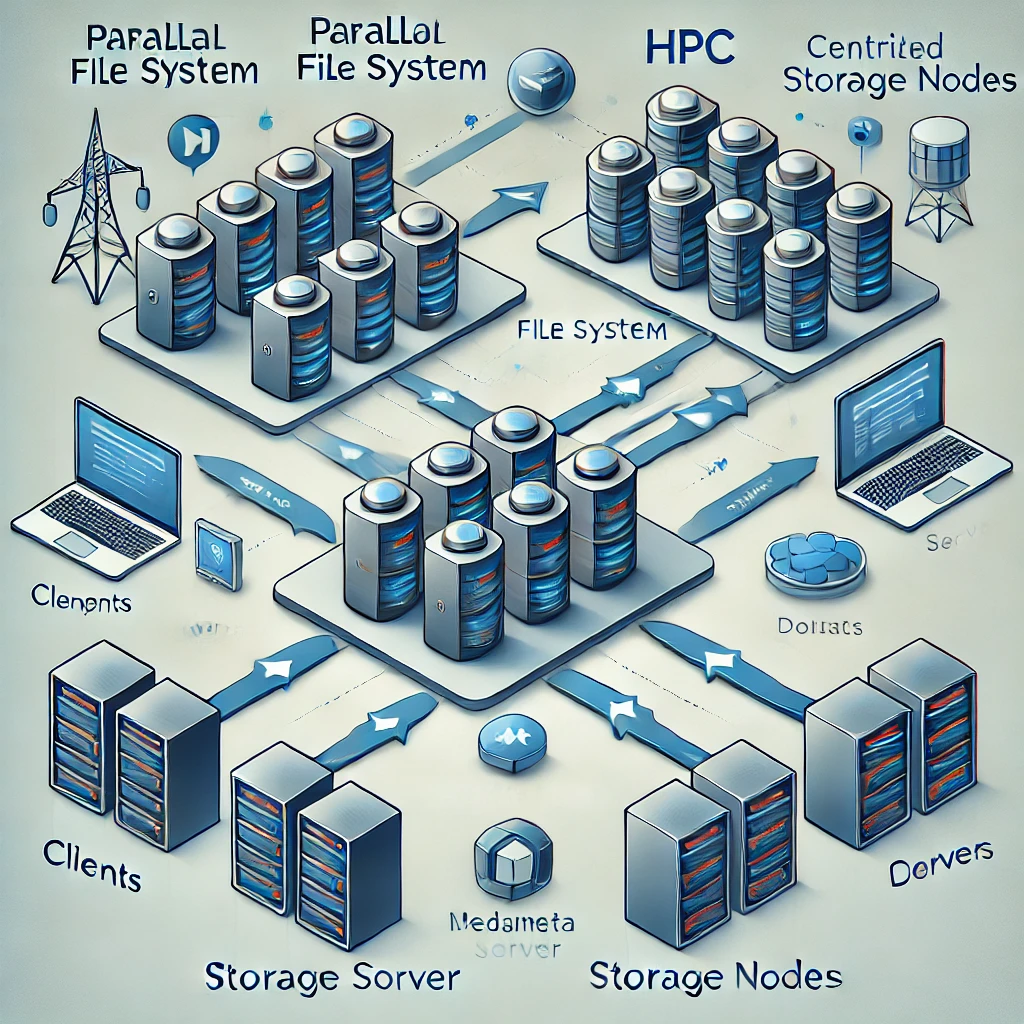
2. 스토리지 그룹
고성능 컴퓨팅 인프라에서 데이터 처리는 매우 중요하며, 이를 위해 스토리지 그룹은 병렬 파일 시스템을 기반으로 설계됩니다. 이 스토리지는 컴퓨팅 시스템이 요구하는 데이터를 신속하게 제공하고, 대규모 데이터셋을 효율적으로 관리합니다. 스토리지 그룹은 단일화된 데이터 보관을 제공하며, 데이터 백업 및 복구 기능도 지원합니다. 이를 통해 중요한 연구 데이터와 결과물이 안전하게 보존되며, 필요시 빠르게 접근할 수 있습니다.
3. 인프라 그룹
인프라 그룹은 사용자와 운영자의 다양한 요구를 충족시키고, 기존의 IT 인프라 및 다른 기관과의 연동을 가능하게 합니다. 이 그룹은 사용자가 인프라를 쉽게 접근하고 활용할 수 있도록 지원하는 포털, API, 그리고 다양한 운영 도구들을 포함합니다. 또한 외부 시스템과의 인터페이스 역할을 하여, 다른 연구 기관 또는 클라우드 자원과의 원활한 연동을 지원합니다.
4. 관리 그룹
전체 인프라를 통합 관리하는 관리 그룹은 시스템의 일관된 운영과 안정성을 책임집니다. 이 그룹은 중앙 관제 기능을 통해 실시간 모니터링, 자원 할당, 성능 최적화, 오류 감지 및 복구를 수행합니다. 또한 관리 네트워크(Ethernet)를 통해 각 그룹 간의 조율과 통합된 접근 방식을 보장합니다. 이를 통해 인프라 전반의 효율적인 운영이 가능하며, 다양한 규모의 컴퓨팅 자원들을 체계적으로 관리할 수 있습니다.
네트워크 구성
이 인프라의 중요한 요소 중 하나는 컴퓨팅 시스템, 스토리지, 인프라 그룹 간의 상호 연결을 담당하는 고성능 네트워크입니다. Interconnect는 컴퓨팅 노드 간 데이터 전송 속도를 최적화하여 병렬 처리를 지원하고, 이더넷 기반의 관리 네트워크는 안정적인 인프라 운영을 지원합니다. 이러한 네트워크는 전체 시스템의 성능과 확장성을 보장합니다.

표준 인프라의 중요성
위에서 설명한 표준 구조는 소규모 연구실에서부터 수만 대의 노드를 보유한 초고성능 슈퍼컴퓨팅 센터까지 폭넓게 적용됩니다. 이러한 구조적 일관성 덕분에 인프라는 필요한 성능과 규모에 맞추어 유연하게 확장될 수 있으며, 시스템 통합 및 운영의 복잡성을 최소화합니다.
결론적으로, AI 및 HPC 인프라는 고성능 컴퓨팅, 데이터 처리, 시스템 통합 및 관리를 위한 표준화된 아키텍처를 통해 다양한 연구 및 산업 분야에서 최상의 성과를 달성할 수 있도록 지원합니다.
AI 및 고성능 컴퓨팅(HPC) 인프라는 규모에 따라 유연하게 확장 가능한 Scale-Out 구조를 기반으로 설계됩니다. 이 구조는 컴퓨팅, 스토리지, 네트워크, 관리 부문에 걸쳐 모든 구성 요소가 유연하게 확장 가능하며, 소규모 시스템에서부터 수천, 수만 대의 노드를 가지는 대규모 인프라로 확장하는 동안에도 중복투자를 최소화합니다.
Scale-Out 구조의 유연성과 경제성
이 인프라는 초기에는 소규모로 저비용에서 시작하여 점진적으로 자원을 추가하는 방식으로 확장이 가능합니다. 예를 들어, 컴퓨팅 시스템 그룹은 소수의 노드에서 시작해 필요에 따라 GPU, NPU 등의 자원을 단계적으로 추가할 수 있으며, 스토리지 그룹도 초기에는 작은 용량의 병렬 파일 시스템으로 시작해 데이터 증가에 따라 스토리지 용량을 손쉽게 확장할 수 있습니다. 이러한 확장 과정에서 기존 시스템을 대체하거나 중복 투자 없이, 기존 인프라와의 원활한 통합을 보장합니다.
안정적인 대규모 인프라 구현
Scale-Out 구조의 장점은 단순히 자원을 추가하는 것에 그치지 않고, 인프라 전체의 안정성과 효율성을 보장하는 데 있습니다. 각 구성 요소는 독립적으로 확장되며, 고성능 네트워크(Interconnect)를 통해 효율적으로 연결되어 병목 현상을 최소화합니다. 또한, 스토리지와 컴퓨팅 자원이 각각 독립적으로 확장 가능하다는 점에서, 필요에 따라 컴퓨팅 성능과 저장 용량을 유연하게 조정할 수 있습니다.
대규모 슈퍼컴퓨팅 센터까지 대응 가능한 검증된 구조
이 표준화된 아키텍처는 소규모 연구 환경에서 시작해 수천 대 이상의 노드로 구성된 대규모 슈퍼컴퓨팅 센터까지 적용됩니다. 확장 과정에서의 일관된 관리와 성능 최적화 덕분에, 다양한 크기의 인프라에서도 높은 효율성과 안정성을 유지합니다. 특히, 중앙 관리 시스템을 통해 전체 인프라를 일관되게 제어할 수 있어, 노드 수가 증가하더라도 시스템 복잡성의 증가 없이 일관된 관리와 운영이 가능하며, 이 구조는 이미 25년 이상 수만개 이상의 슈퍼컴퓨팅 구축사례에 적용된 검증된 아키텍처입니다.

요약
AI 및 고성능 컴퓨팅 인프라는 유연한 Scale-Out 구조를 통해 저비용으로 소규모에서 시작해 필요에 따라 수천, 수만 대의 노드로 확장할 수 있으며, 중복투자 없이 안정적이고 효율적인 성능을 보장합니다. 이러한 구조는 다양한 연구 환경과 산업 분야에서 최적의 성능과 확장성을 제공하여, 소규모 연구실부터 대규모 슈퍼컴퓨팅 센터까지 효과적으로 대응할 수 있습니다.